- azure
- bitbucketCloud
- bitbucketServer
- gerrit
- gitea
- github
- gitlab
Prerequisites
SCM Integrations - Connecting the SCM module to SCM providers
To connect to external providers, an ‘integration’ must be provided in the mainapp-config.yaml file
as follows:
host set to github.com. Authentication is provided
via a token issued from github.com for the repository that you’d like to connect to.
Consult the Backstage GitHub integration instructions for full configuration details.
Add the ScmFactCollector to Soundcheck
Source Control Management integration for Soundcheck is not installed by default. It must be manually installed and configured. First, add the@spotify/backstage-plugin-soundcheck-backend-module-scm package:
packages/backend/src/index.ts file:
packages/backend/src/index.ts
Adding SCM Entities
To use Source Control Management (SCM) integrations, an entity hosted by an SCM provider is needed. As an example, an entity could be added to the catalog with atype set to url and a target set to the entity’s hosted location, like so:
github.com and configured by the target yaml
file.
Entity configuration
To be able to determine the location of a file the SCM integration will use the value from thebackstage.io/source-location annotation as its base. In many cases this will be set for you but if it is not you will need to add it to your catalog-info.yaml file, here’s a simple example:
Configuring the SCM Module
SCM Fact Collector can be configured via YAML, URL or No-Code UI. If you configure it via both YAML and No-Code UI, the configurations will be merged. It’s preferable to choose a single source for the Fact Collectors configuration (either No-Code UI, YAML or URL) to avoid confusing merge results.SCM Fact Collector: No-Code UI Configuration Option
- Make sure the prerequisite SCM Integrations - Connecting the SCM module to SCM providers is completed and SCM instance details are configured.
-
To configure the SCM Integration, go to
Soundcheck > Integrations > Source Code Managementand click theConfigurebutton. To learn more about the No-Code UI config, see the Configuring a fact collector (integration) via the no-code UI.
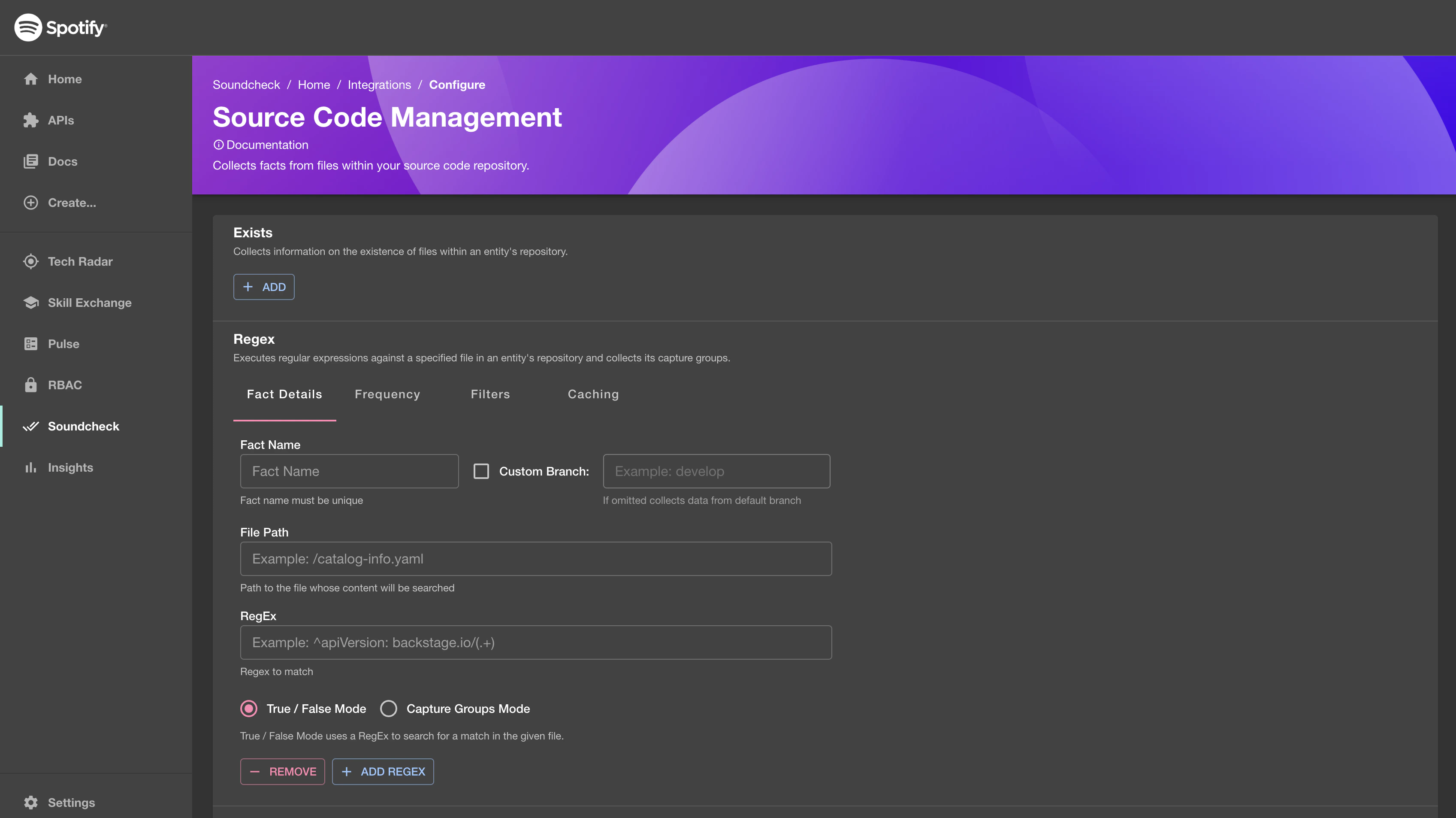
SCM Fact Collector: YAML Configuration Option
The facts to be collected by the Source Control Management (SCM) module must be defined in one or moreyaml files, and then
referenced in the Soundcheck configuration in the app-config.yaml file, like so:
soundcheck.collectors.scm field, your Backstage instance is almost ready to extract facts from SCM providers.
The next section covers how to set up the fact extraction configuration files to extract facts from
SCM.
SCM Fact Collector: URL Configuration Option
The SCM Fact Collector can be configured to fetch its configuration from one or more remote URLs, allowing its configuration to be managed as code. The configuration files still follow the rules and structure as outlined for collectors above. Here is how the SCM Fact Collector can be configured to fetch its configuration from remote URLs:app-config.yaml
scm collector accepts an array of URL strings pointing to remote configuration files.
Multiple URLs can be provided, and configurations from all URLs will be included.
Rate Limiting (Optional)
This fact collector can be rate limited in Soundcheck using the following configuration:Caching Full Etag Responses (Optional)
The SCM Fact Collector can be configured to cache the full response from the SCM provider when using ETags. This will cache not only the extracted fact data, but the full response from the SCM provider, including the file tree structure and file contents. This is especially useful when using GLOB paths that may return many files as it can save significantly on API calls to the SCM provider(s). If you’re encountering API rate limits and are using GLOB patterns, consider enabling this option. WARNING: Caching full responses can lead to high memory usage, particularly when using GLOB patterns that match many files or if the files themselves are large. Enable this option with:SCM Fact Extraction Configuration
The SCM Fact Collector configurationyaml files have the following structure:
frequency [Optional]
The frequency at which the collector should be executed. Possible values are either a cron expression { cron: ... } or HumanDuration.
This is the default frequency for each extractor.
initialDelay [optional]
The amount of time that should pass before the first invocation happens. Possible values are either a cron expression { cron: ... } or HumanDuration.
batchSize [optional]
The number of entities to collect facts for at once. Optional, the default value is 1.
Note: Fact collection for a batch of entities is still considered as one hit towards the rate limits
by the Soundcheck Rate Limiting engine, while the actual number of hits
will be equal to the batchSize.
Example:
filter [Optional]
A filter specifying which entities to collect the specified facts for. Matches the filter format used by the Catalog API.
This is the default filter for each extractor.
See filters for more details.
exclude [optional]
Entities matching this filter will be skipped during the fact collection process. Can be used in combination with filter. Matches the filter format used by the Catalog API.
cache [Optional]
If the collected facts should be cached, and if so for how long. Possible values are either true or false or a nested { duration: HumanDuration } field.
This is the default cache config for each extractor.
collects
An array of SCM Fact Extractor configurations describing how to collect SCM facts. See the section
below for details on configuring the extractors.
SCM Fact Extractors
The Exists, RegEx, JSON and YAML, XML, and Code Search Source Control Management (SCM) fact extractor configurations are described in detail below. Before going into the detailed schemas of the individual fact extractors, the base schema that they all share will be covered first.Common Fact Extractor Schema
All SCM Fact Extractors share a common base schema, the variables for which are defined below:factName
The name of the fact to be extracted.
- Minimum length of 1
- Maximum length of 100
- Alphanumeric with single separator instances of periods, dashes, underscores, or forward slashes
filter [Optional]
A filter specifying which entities to collect the specified facts for. Matches the filter format used by the Catalog API.
If provided, it overrides the default filter provided at the top level. If not provided, it defaults to the filter provided at the top level. If neither extractor’s filter, nor default filter is provided, the fact will be collected for all entities.
exclude [optional]
Entities matching this filter will be skipped during the fact collection process. Can be used in combination with filter. Matches the filter format used by the Catalog API.
cache [Optional]
If the collected facts should be cached, and if so for how long. Possible values are either true or false or a nested { duration: HumanDuration } field.
If provided, it overrides the default cache config provided at the top level. If not provided, it defaults to the cache config provided at the top level. If neither extractor’s cache, nor default cache config is provided, the fact will not be cached.
Example:
frequency [optional]
The frequency at which the fact extraction should be executed. Possible values are either a cron expression { cron: ... } or HumanDuration.
If provided, it overrides the default frequency provided at the top level. If not provided, it defaults to the frequency provided at the top level. If neither extractor’s frequency, nor default frequency is provided, the fact will only be collected on demand.
Example:
batchSize [optional]
The number of entities to collect facts for at once. Optional, the default value is 1.
If provided it overrides the default batchSize provided at the top level. If not provided it defaults to the batchSize provided at the top level. If neither collector’s batchSize nor default batchSize is provided the fact will be collected for one entity at a time.
Note: Fact collection for a batch of entities is still considered as one hit towards the rate limits
by the Soundcheck Rate Limiting engine, while the actual number of hits
will be equal to the batchSize.
Example:
branch [optional]
The branch to extract the fact from. If not provided, defaults to the repository’s default branch.
Branch names containing
/ are not supported and silently return empty fact
data. Use a single-segment name (e.g. replace / with -). Tracked upstream
in
backstage/backstage#2815
and #32727.Exists Fact Extractor
The Exists Fact Extractor collects information on whether a given file exists in the SCM provider. The extensions to the base schema are as follows:type
Must be exactly exists, like so:
data
The data collected for this fact. This is an array consisting of two pairs of name and path:
name: An identifier for the data element.path: The path to the file. GLOB paths are supported.
name and path are subject to the naming restrictions of factName.
Sample Exists Configuration
Here’s a sampleyaml configuration for a fact that gets information on the
existence of two files, README.md and catalog-info.yaml:
app-config.yaml file. Since this fact collects two data elements, there will be
two checks that check the value of each data element. The two checks would look like this:
ordinal within the soundcheck-tracks.yaml file. Here’s an example:
RegEx Fact Extractor
The RegEx Fact Extractor collects information about the contents of a file. Two modes are supported:True/False Mode
True/False Mode uses a Regular Expression, or RegEx, to search for a match in a specified file. If a RegEx match is found, the resulting fact data will contain a value oftrue for a field named matches. If not, the
matches field will contain a value of false.
RegEx Capture Groups Mode
Using RegEx Capture Groups Mode allows the extractor to associate capture groups within a RegEx to named values. This allows checks to verify that the captured values are correct.RegEx Fact Extractor Schema
The extension schema for RegEx Fact Extractors is as follows:type
Must be exactly regex, like so:
path
The path to the file to analyze. GLOB paths are supported. When GLOB paths are used, the fact data
will be an array, with each element corresponding to a file that matched the GLOB path. If true/false
mode is used, array will contain objects with a matches field, which will be true if the file
matched the RegEx, and false if it did not. If RegEx Capture Groups Mode is used, the array will
contain objects with fields corresponding to the capture groups defined in the RegEx.
NOTE: When using GLOB paths, ensure your check is prepared to handle an array of results. See
the example below.
regex
A valid RegEx string. This string is used on the file to collect data elements or to provide a true/false response corresponding to whether there is a match for the RegEx or not in the file.
flags [Optional]
Accepts an optional regex flag parameter that must match:
/^[gimsuy]+$/
g | Global search.
i | Case-insensitive search.
m | Allows ^ and $ to match next to newline characters.
s | Allows . to match newline characters.
u | “Unicode”; treat a pattern as a sequence of Unicode code points.
y | Perform a “sticky” search that matches starting at the current position in the target string.
A sample fact using the configuration is as follows:
data [Optional]
Defines the data to collect for this fact. This is an array consisting of two pairs of name and
type:
name: An identifier for the data element. Subject to the naming restrictions of factName.type: The expected type of data to be collected.
regex. A mismatch between data element definition counts and RegEx Capture Groups is an error. Fact
data will not be collected.
If the data element is not present, the mode of the RegEx Fact Extractor defaults to True/False Mode.
Sample RegEx Configuration
Theyaml below defines both modes of the RegEx Extractor, True/False Mode and RegEx Capture Groups Mode.
Sample fact definitions are as follows:
app-config.yaml file. Here are sample checks that correspond to
the RegEx facts above:
soundcheck-tracks.yaml file under an appropriate track level ordinal of a track. Here’s an example:
readme-a.md and readme-b.md. The contents of these files are as follows:
readme-a.md:
parsedVersion. So, the fact data that gets generated for this fact will look like this based on
the files above:
parsedVersion array must be greater than 0.5, and so
the check will pass in this example.
JSON and YAML Fact Extractor
The final fact extractor type supported by the Source Control Management (SCM) plugin is the JSON and YAML Fact Extractor. It works similarly to the RegEx Fact Extractor in that it extractsjson/yaml values from a file for use in checks.
JSON and YAML Fact Extractor Schema
The extension schema for JSON and YAML Fact Extractors is as follows:type
Must be one of json or yaml, like so:
path
The path to the file to analyze. GLOB paths are supported. When GLOB paths are used, the fact data
will be an array, with each element corresponding to a file that matched the GLOB path.
data
Defines the data to collect for this fact. This is an array of the following fields:
name: An identifier for the data element. Subject to the naming restrictions of factName.type: The expected type of data to be collected, eitherarrayor a primitive type (string,int, etc.)jsonPath: A period delimited path to the desiredjson/yamlelement.items: A optional field with a singletypeproperty. If included, the data returned by the fact will be an array of all matching elements of the specified type. If omitted, the returned value will be a single element.
Sample JSON and YAML Configuration
Theyaml below defines both collection types performed by the JSON and YAML Extractor: single element capture and array
capture.
Sample fact definitions are as follows:
data specifications correspond to the two types supported by this extractor, arrays
and strings, respectively. The jsonPath of metadata.tags will be extracted into an array named tags
of type string. The jsonPath of metadata.annotations.pagerduty_integration-key will be extracted into a
variable called pager_duty_integration_key of type string.
The checks for the fact data extracted by the fact specification above could be as follows:
tags array is not undefined in the file,
meaning that there are tags present. The second check ensures that the pager_duty_integration_key is in the
file and that it is equal to the given value.
Finally, these two checks are added to the soundcheck-tracks.yaml file, under an appropriate track level ordinal. Here’s an example:
soundcheck-tracks.yaml means that they must pass for the corresponding track and level to be considered as passing.
XML Fact Extractor
The XML Fact Extractor extracts data from XML files in the SCM provider. It works similarly to the JSON and YAML Fact Extractor, usingjsonPath expressions to extract values from XML files.
Unlike JSON/YAML, XML The
jsonPath expressions must include the root element name. For example, given an XML file like:jsonPath should be: $.Project.PropertyGroup.TargetFramework@_ prefix. For example, given:
Sdk attribute can be accessed with jsonPath: $.Project.@_Sdk
XML Fact Extractor Schema
The extension schema for XML Fact Extractors is as follows:type
Must be exactly xml, like so:
path
The path to the XML file to analyze. GLOB paths are supported. When GLOB paths are used, the fact data will be an array, with each element corresponding to a file that matched the GLOB path.
data
Defines the data to collect for this fact. This is an array of the following fields:
name: An identifier for the data element. Subject to the naming restrictions of factName.type: The expected type of data to be collected, eitherarrayor a primitive type (string,int, etc.)jsonPath: A period delimited path to the desired XML element. Must include the root element name.items: An optional field with a singletypeproperty. If included, the data returned by the fact will be an array of all matching elements of the specified type. If omitted, the returned value will be a single element.
Sample XML Configuration
This example demonstrates how to extract the target framework from a .NET project file (.csproj).
Given a .csproj file like:
soundcheck-tracks.yaml file:
Code Search Fact Extractor
The Code Search Fact Extractor uses the SCM provider’s code search API to find code patterns across a repository without downloading individual files. This is useful when you need to verify the presence (or absence) of specific code patterns, imports, or configuration values across an entire repository.Code search is currently only supported for GitHub repositories. The extractor
uses GitHub’s Code Search
API.
GitHub’s Code Search API does not support branch scoping — searches always run
against the repository’s default branch regardless of any
branch
configuration.Code Search Fact Extractor Schema
The extension schema for Code Search Fact Extractors is as follows:type
Must be exactly code-search, like so:
query
The search query string to find in the repository. This is the text or pattern to search for (e.g., "import express", "FROM node:18").
- Minimum length of 1
qualifiers [Optional]
Optional qualifiers to narrow the search scope. These are appended to the query as GitHub search qualifiers.
Fact Data Schema
The fact data returned by the Code Search extractor has the following shape:
For entities in a monorepo, the search is automatically scoped to the entity’s subdirectory based on its
backstage.io/source-location annotation.
Sample Code Search Configuration
Theyaml below defines two code search facts: one that checks whether any file imports express, and another that checks whether a Dockerfile uses a node base image.
Sample fact definitions are as follows:
soundcheck-tracks.yaml file:
YAML Anchor Support
The SCM collector supports YAML anchor parsing and resolution within the same file. There are some limitations when using the!reference tag, and can only resolve references in the same file.
Appendix
Basic SCM Compliance Fact Collector
Pre-builtBasic SCM Compliance checks are based on the following collector configuration: