- Query - contains information returned as a result of execution of Google SQL query.
Prerequisites
Configure BigQuery authentication in Backstage
The authentication is configured at the root level ofapp-config.yaml. Here’s an example configuration for BigQuery:
auth [optional]
An array of Google Cloud authentication config. The authentication configuration is optional,
alternatively you can set up Application Default Credentials by following the
Google documentation.
projectId [required]
Google Cloud Project ID.
keyFilename [optional]
Path to a .json, .pem, or .p12 key file to use for authentication.
Either keyFilename or credentials must be provided if Application Default Credentials are not set up.
credentials [optional]
JSON object containing client_email and private_key properties (the content of .json key file).
Either keyFilename or credentials must be provided if Application Default Credentials are not set up.
Add the BigQueryCollector to Soundcheck
First, add the@spotify/backstage-plugin-soundcheck-backend-module-bigquery package:
packages/backend/src/index.ts file:
packages/backend/src/index.ts
Plugin Configuration
The collection of BigQuery facts is driven by configuration. To learn more about the configuration, consult the Defining BigQuery Fact Collectors section. BigQuery Fact Collector can be configured via YAML or No-Code UI. If you configure it via both YAML and No-Code UI, the configurations will be merged. It’s preferable to choose a single source for the Fact Collectors configuration (either No-Code UI or YAML) to avoid confusing merge results.No-Code UI Configuration Option
- Make sure the prerequisite Configure BigQuery authentication in Backstage is completed and BigQuery authentication is configured.
-
To enable the BigQuery Integration, go to
Soundcheck > Integrations > BigQueryand click theConfigurebutton. To learn more about the No-Code UI config, see the Configuring a fact collector (integration) via the no-code UI.
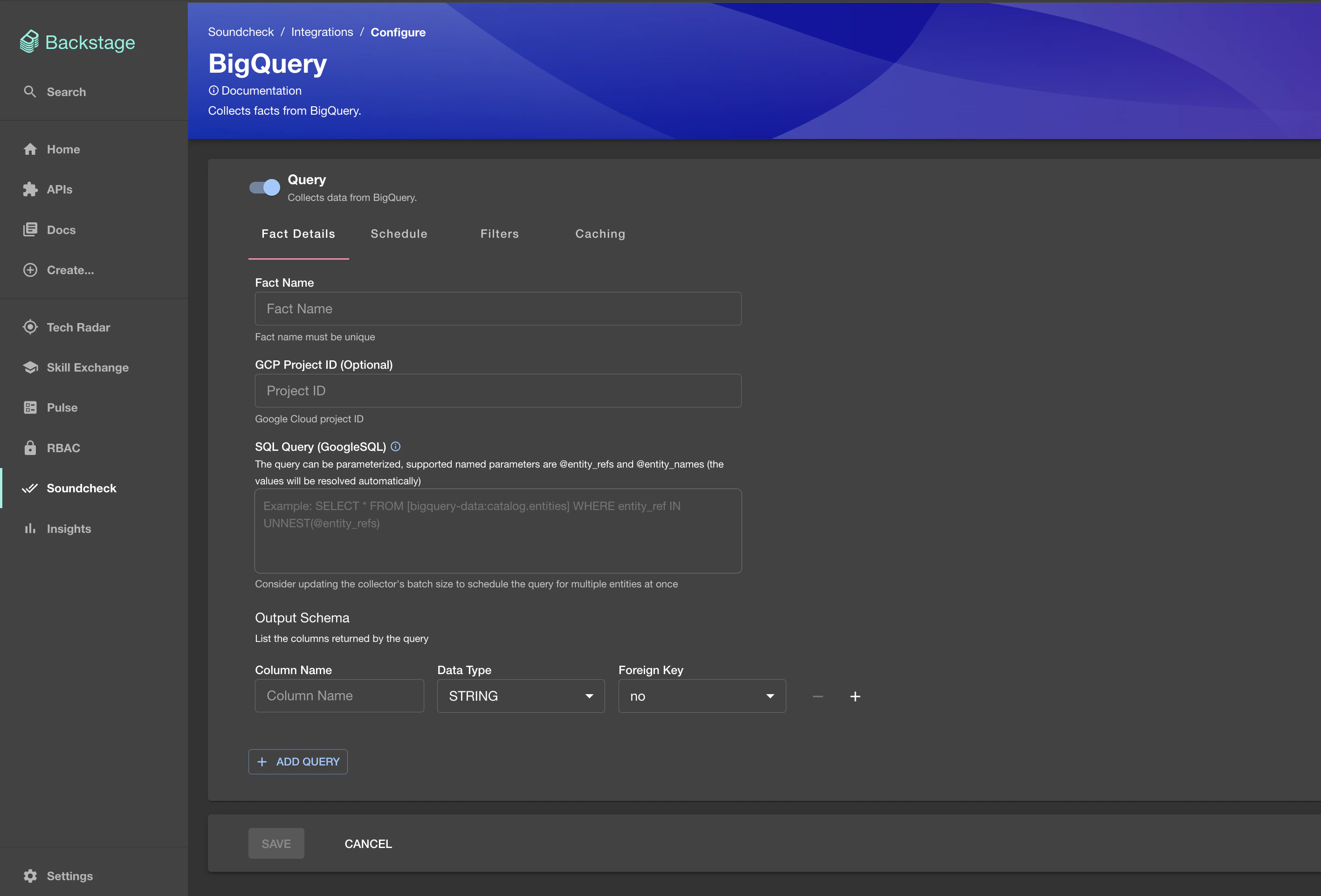
YAML Configuration Option
- Create a
bigquery-facts-collectors.yamlfile in the root of your Backstage repository and fill in all your BigQuery Fact Collectors. A simple example BigQuery fact collector is listed below.
app-config.yaml files.
- Add a Soundcheck collects field to the
app-config.yamland reference the newly createdbigquery-facts-collectors.yamlfile.
Defining BigQuery Fact Collectors
This section describes the data shape and semantics of BigQuery Fact Collectors.Shape Of A BigQuery Fact Collector
The following is an example of a BigQuery Fact Collector YAML configuration:collects [required]
An array describing which facts to collect.
factName [required]
The name of the fact to be collected.
- Minimum length of 1
- Maximum length of 100
- Alphanumeric with single separator instances of periods, dashes, underscores, or forward slashes
type [required]
The type of the collector: query.
projectId [optional]
Google Cloud Project ID. If provided and matches one of the project IDs from the auth section,
the corresponding config will be used for the authentication.
query [required]
SQL Query (GoogleSQL).
The query can be parameterized, supported named parameters are @entity_refs and @entity_names.
The values will be resolved automatically when the fact collection is scheduled.
-
@entity_refs- the references of all entities in a batch (values in the formatkind:namespace/name). Value example:['component:default/queue-proxy', 'component:default/petstore']. Usage example:WHERE column IN UNNEST(@entity_refs). -
@entity_names- the names of all entities in a batch (entity’smetadata.namevalue). Value example:['queue-proxy', 'petstore']. Usage example:WHERE column IN UNNEST(@entity_names).
@entity_refs nor @entity_names parameter is used within the query,
the same data will be collected for each entity batch (this behaviour may be desired if you don’t want
to run a heavy query multiple times for different sets of entities).
The same queries are executed only once during every scheduled run (the collector prevents executing
the same query more than once even across different entity batches by caching the query response until
the next scheduled run).
schema [optional]
An array describing the columns returned by the query. Optional, if not provided the available
fact paths won’t be auto-populated in Check Creation No-Code UI
and you won’t be able to group the query response by an entity if batchSize is configured.
-
name[required] - the name of the column. -
type[optional] - the column’s data type (optional, default value isstring). -
isEntityRef[optional] - set totrueif the column contains entity references (values in the formatkind:namespace/name). Such column will be treated as a foreign key that referencesEntity(entity_ref), so that the query response will be grouped by the values in this column and the resulting entity fact will only contain the group that corresponds to the entity. -
isEntityName[optional] - set totrueif the column contains entity names (entity’smetadata.namevalue). Such column will be treated as a foreign key that referencesEntity(metadata.name), so that the query response will be grouped by the values in this column and the resulting entity fact will only contain the group that corresponds to the entity.
frequency [optional]
The frequency at which the fact collection should be executed. Possible values are either a cron expression { cron: ... } or HumanDuration.
If provided, it overrides the default frequency provided at the top level. If not provided, it defaults to the frequency provided at the top level. If neither collector’s frequency nor default frequency is provided, the fact will only be collected on demand.
Example:
initialDelay [optional]
The amount of time that should pass before the first invocation happens. Possible values are either a cron expression { cron: ... } or HumanDuration.
Example:
batchSize [optional]
The number of entities to collect facts for at once. Optional, the default value is 1.
Example:
filter [optional]
A filter specifying which entities to collect the specified facts for. Matches the filter format used by the Catalog API.
If provided, it overrides the default filter provided at the top level. If not provided, it defaults to the filter provided at the top level. If neither collector’s filter nor default filter is provided, the fact will be collected for all entities.
See filters for more details.
exclude [optional]
Entities matching this filter will be skipped during the fact collection process. Can be used in combination with filter. Matches the filter format used by the Catalog API.
cache [optional]
If the collected facts should be cached, and if so for how long. Possible values are either true or false or a nested { duration: HumanDuration } field.
If provided it, overrides the default cache config provided at the top level. If not provided, it defaults to the cache config provided at the top level. If neither collector’s cache nor default cache config is provided, the fact will not be cached.
Example:
Rate Limiting (Optional)
This fact collector can be rate limited in Soundcheck using the following configuration:rateLimitExceeded and quotaExceeded error codes from BigQuery. Soundcheck will automatically wait and retry requests that are rate limited.
Shape of A BigQuery Fact
The shape of a BigQuery Fact is based on the Fact Schema. The following is an example of the collected BigQuery fact:rows as a top level field and collected rows as
a nested array.