Overview
Soundcheck integrations (also called Fact Collectors) are responsible for collecting data about your Backstage entities from third-party services. A single piece of data collected about an entity is called a Fact. Facts are then referenced in Soundcheck Checks to determine whether an entity adheres to the rules you’ve defined. Soundcheck comes with a set of pre-built integrations out-of-the-box, including GitHub, PagerDuty, Datadog, and more. However, you may need to create custom integrations to collect different types of data or connect to internal services specific to your organization.It is not possible to extend or modify pre-built fact collectors shipped by
Soundcheck. If you need extra functionality, you must create a custom
integration or use the HTTP
integration
for simpler use cases.
ExamplePagerDutyFactCollector that retrieves service details from PagerDuty for entities annotated with a pagerduty.com/service-id.
Time to complete: ~30 minutes
Prerequisites
Before starting, ensure you have:Implementation
Step 1: Create the Backend Module
Use the Backstage CLI to create a new backend module for your integration:
You’ll see: “Successfully created backend-plugin-module.”
Next, install the required packages:
From your Backstage root directory
Step 2: Create the Fact Collector
Create a new file calledExamplePagerDutyFactCollector.ts in the src folder of your new module.
- 1. Imports & Constants
- 2. Class Structure
- 3. collect() Method
- 4. Metadata Methods
- 5. Collection Config
- 6. Configuration Methods
- Complete Code
Start with the imports and constants:
src/ExamplePagerDutyFactCollector.ts
📖 What do these imports and constants mean?
📖 What do these imports and constants mean?
Key imports:
Constants:
Step 3: Register the Module
Update themodule.ts file in your backend module to register the fact collector:
src/module.ts
- The module declares a dependency on
factCollectionExtensionPoint—an extension point exposed by Soundcheck that allows external modules to register custom fact collectors. - During initialization, it calls
addFactCollector()to register ourExamplePagerDutyFactCollectorwith Soundcheck’s fact collection system. - Once registered, Soundcheck manages the collector’s lifecycle, including scheduling fact collection based on the
frequencyyou define inapp-config.yaml.
Step 4: Configure Your Integration
4.1 Add the collector configuration
Add the following to yourapp-config.yaml:
app-config.yaml
📖 Advanced: Multiple collection schedules
📖 Advanced: Multiple collection schedules
You can define multiple collection schedules with different filters and frequencies:
app-config.yaml
4.2 Annotate your entities
Add the PagerDuty service annotation to entities that should be tracked:catalog-info.yaml
Step 5: Create Checks and Tracks
Add checks and tracks to yourapp-config.yaml under the same soundcheck: key you configured in Step 4.
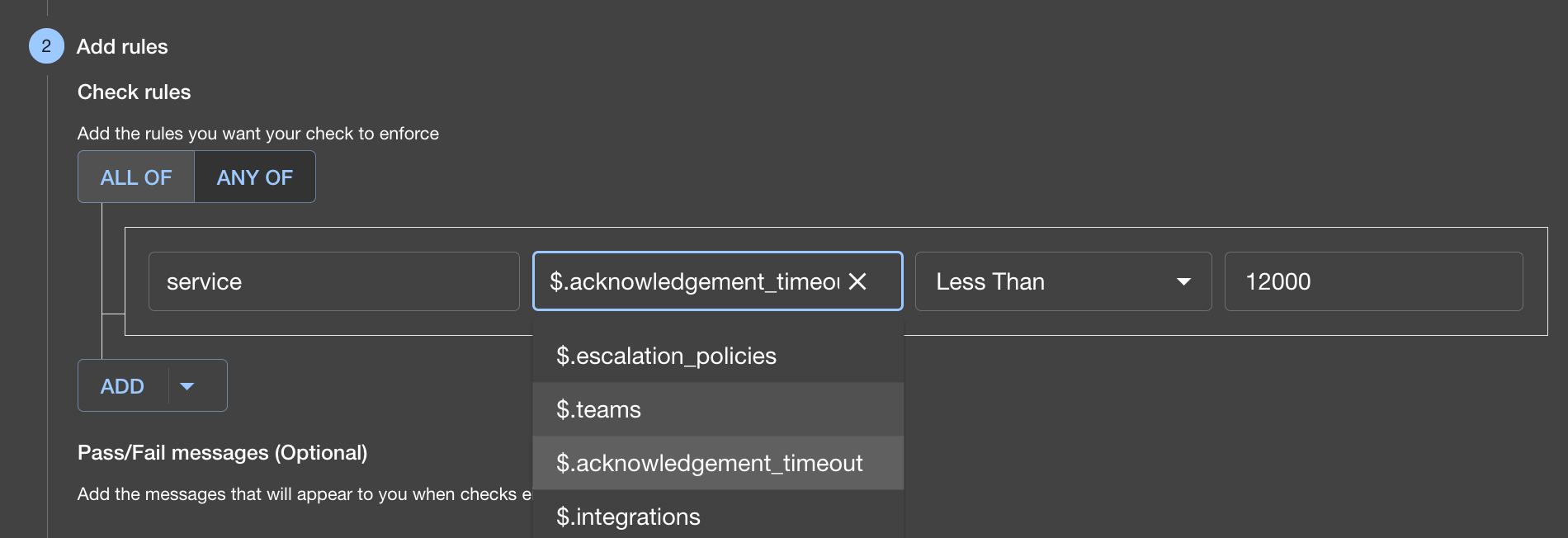
5.1 Define a check
Add achecks section to use the collected facts:
app-config.yaml
Why no schedule on this check?Notice this check has no
schedule property. This is intentional—Soundcheck automatically triggers any check when the facts it depends on are collected.Since this check references example-pagerduty:default/service in its factRef, it will run automatically whenever our ExamplePagerDutyFactCollector collects the service fact. The collector runs on the schedule we defined in Step 4 (e.g., every 5 minutes), so the check runs on that same cadence.This is the recommended approach: schedule fact collection, not checks. It ensures checks always evaluate fresh data and respects the rate-limiting settings configured for the collector.5.2 Create a track
Add atracks section to group your checks:
app-config.yaml
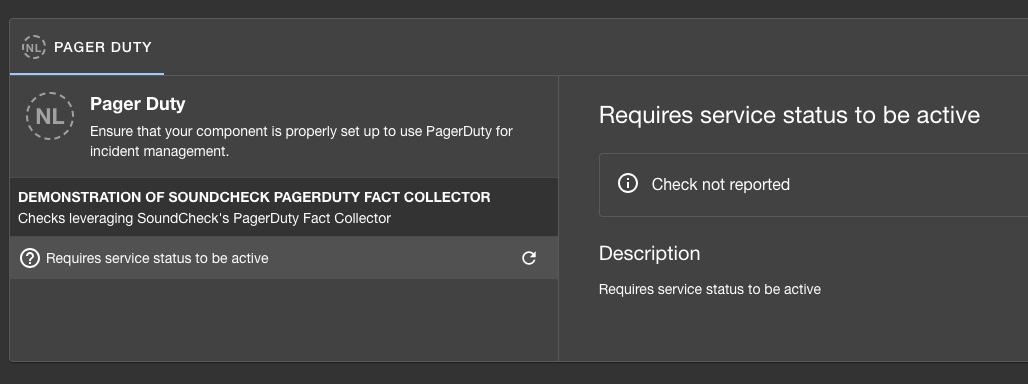
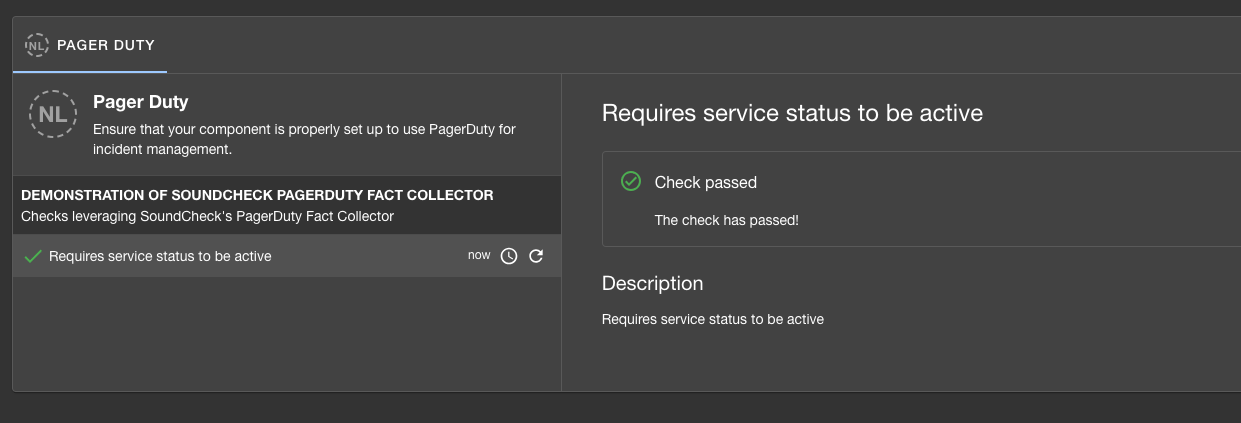
Step 6: Verify Your Integration
- Start your Backstage instance
- Navigate to Soundcheck → Integrations
- Confirm your custom integration appears in the list
frequency), you’ll see the checks execute:
Next Steps
- Create a No-Code UI for your integration to enable configuration through the Soundcheck interface