Prerequisites
Configure Kubernetes Integration in Backstage
Configure kubernetes according to the backstage kubernetes plugin docs. Note: the Kubernetes plugin has the following limitations:- We only support the catalog and config
clusterLocatorMethods. - apiVersionOverrides are currently not supported.
- We only support certain server-side authentication strategies. See authentication section for details.
backstage.io/kubernetes-id annotation.
Labels in Kubernetes
By default, the label selector used to query the kubernetes cluster isapp={backstage.io/kubernetes-id}.
You can use a custom label selector by using the backstage.io/kubernetes-label-selector annotation.
Authentication
Configure your authentication according to the kubernetes plugin. The fact collector only supports the following server side auth strategies:- aws
- azure
- googleServiceAccount
- serviceAccount
Add the Kubernetes Fact Collector to Soundcheck
First, add the@spotify/backstage-plugin-soundcheck-backend-module-kubernetes package:
packages/backend/src/index.ts file:
packages/backend/src/index.ts
Plugin Configuration
Kubernetes Fact Collector can be configured via YAML or No-Code UI. If you configure it via both YAML and No-Code UI, the configurations will be merged. It’s preferable to choose a single source for the Fact Collectors configuration (either No-Code UI or YAML) to avoid confusing merge results.No-Code UI Configuration Option
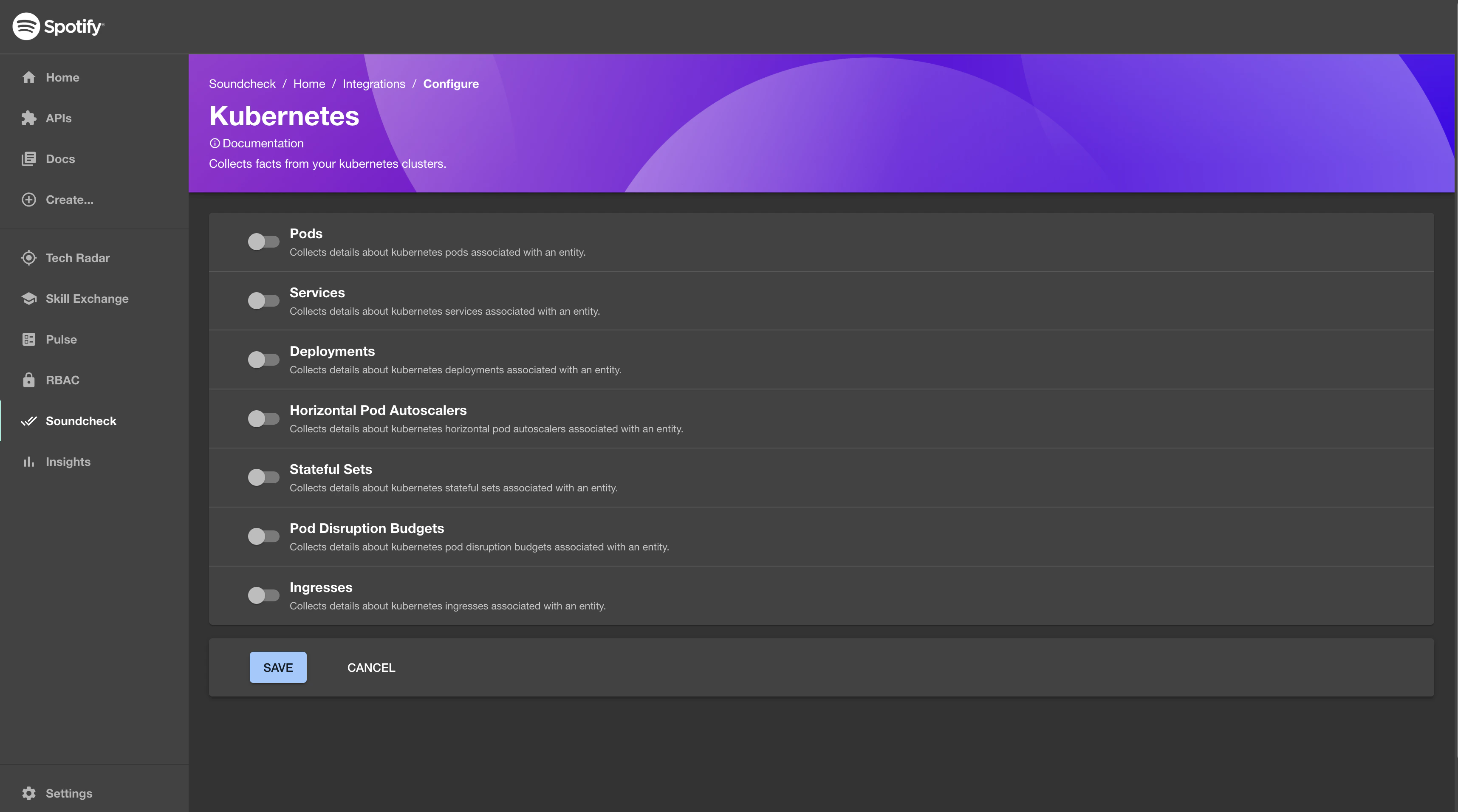
- Make sure the prerequisite Configure Kubernetes integration in Backstage is completed and Kubernetes instance details are configured.
-
To enable the Kubernetes Integration, go to
Soundcheck > Integrations > Kubernetesand click theConfigurebutton. To learn more about the No-Code UI config, see the Configuring a fact collector (integration) via the no-code UI.
YAML Configuration Option
- Create a
kubernetes-facts-collectors.yamlfile in the root of your Backstage repository to use for configuration.
kubernetes-facts-collectors.yaml
app-config.yaml files are.
-
Add a soundcheck collectors field to
app-config.yamland reference the newly createdkubernetes-facts-collectors.yamlapp-config.yaml
Rate Limiting (Optional)
This fact collector can be rate limited in Soundcheck using the following configuration:Defining Kubernetes Fact Collector
This section describes the data shape and semantics of Kubernetes Fact Collector.Overall Shape Of A Kubernetes Fact Collector
The following is an example of a descriptor file for a Kubernetes Fact Collector:frequency [optional]
The frequency at which the collector should be executed. Possible values are either a cron expression { cron: ... } or HumanDuration.
This is the default frequency for each fact type.
Example:
initialDelay [optional]
The amount of time that should pass before the first invocation happens. Possible values are either a cron expression { cron: ... } or HumanDuration.
This is the default initial delay for each fact type.
Example:
batchSize [optional]
The number of entities to collect facts for at once. Optional, the default value is 1.
Note: Fact collection for a batch of entities is still considered as one hit towards the rate limits
by the Soundcheck Rate Limiting engine, while the actual number of hits
will be equal to the batchSize.
Example:
filter [optional]
A filter specifying which entities to collect the specified facts for. Matches the filter format used by the Catalog API.
This is the default filter for each fact type.
Example:
exclude [optional]
Entities matching this filter will be skipped during the fact collection process. Can be used in combination with filter. Matches the filter format used by the Catalog API.
cache [optional]
If the collected facts should be cached, and if so for how long. Possible values are either true or false or a nested { duration: HumanDuration } field.
This is the default cache config for each fact type.
Example:
google [optional]
This is used for GKE authentication. By default that auth strategy uses the application default credentials. However, you can pass in a JSON key to use instead.
collects [required]
An array describing which facts to collect and how to collect them. See below for details about the configuration of fact collection for each fact type.
-
The type of the collector. The following types are available:type[required] -
The frequency at which the fact collection should be executed. Possible values are either a cron expressionfrequency[optional]{ cron: ... }or HumanDuration. If provided, it overrides the default frequency provided at the top level. If not provided, it defaults to the frequency provided at the top level. If neither collector’s frequency, nor default frequency is provided, the fact will only be collected on demand. -
The amount of time that should pass before the first invocation happens. Possible values are either a cron expressioninitialDelay[optional]{ cron: ... }or HumanDuration. If provided, it overrides the default initial delay provided at the top level. If not provided, it defaults to the initial delay provided at the top level. If neither collector’s initial delay, nor default initial delay is provided, the fact will be collected with no initial delay. -
The number of entities to collect facts for at once. Optional, the default value is 1. If provided it overrides the default batchSize provided at the top level. If not provided it defaults to the batchSize provided at the top level. If neither collector’s batchSize nor default batchSize is provided the fact will be collected for one entity at a time. Note: Fact collection for a batch of entities is still considered as one hit towards the rate limits by the Soundcheck Rate Limiting engine, while the actual number of hits will be equal to thebatchSize[optional]batchSize. Example: -
A filter specifying which entities to collect the specified facts for. Matches the filter format used by the Catalog API. If provided, it overrides the default filter provided at the top level. If not provided, it defaults to the filter provided at the top level. If neither collector’s filter, nor default filter is provided, the fact will be collected for all entities.filter[optional] -
Entities matching this filter will be skipped during the fact collection process. Can be used in combination with filter. Matches the filter format used by the Catalog API.exclude[optional] -
If the collected facts should be cached, and if so for how long. Possible values are eithercache[optional]trueorfalseor a nested{ duration:HumanDuration}field. If provided, it overrides the default cache config provided at the top level. If not provided, it defaults to the cache config provided at the top level. If neither collector’s cache nor default cache config is provided, the fact will not be cached. -
The name of a Kubernetes subresource to collect instead of the parent resource itself. The value must be a lowercase alphabetic string (e.g.,subresource[optional]status,scale,log). Whensubresourceis set, the collector performs a two-step fetch:- List the parent resources (e.g., all pods matching the label selector).
- Fetch the subresource for each individual item (e.g.,
GET /api/v1/namespaces/{ns}/pods/{name}/status).
{factName or type}_{subresource}. For example,type: k8s_podswithsubresource: statusproduces the fact namek8s_pods_status. If afactNameis also provided, it is used as the base:factName: my_deploywithsubresource: scaleproducesmy_deploy_scale. All derived fact names across collect entries must be unique. Example:See Subresource fact schema for the result data shape.
Custom Resources
Custom resources for kubernetes are supported. Each custom resource needs to be defined with a unique fact name. ThecustomResource property needs to be defined and is similar to the kubernetes plugin’s customResources.
Example:
subresource field alongside customResource:
k8s_crontabs_status.
If a custom resource api is not present on a cluster, the fact will return a resourceMissing property.
Example:
Collecting Facts
All kubernetes fact collections fetch data from the kubernetes api.Schema
The general type of each fact type is as follows:clusters
A list of cluster names where the items were retrieved from.
labelSelector
The label selector used to query the clusters.
items
A list of retrieved items. If there are items from multiple clusters, that are combined into this items list.
-
The spec contains data specific to the fact type. See the following table:spec -
This is the common kubernetes ObjectMetadata object.metadata -
The cluster this item comes from.clusterName
Example Fact
Example fork8s_deployments in JSON:
Subresource Fact Schema
When a collect entry includes asubresource field, the resulting fact has a different item shape. Instead of spec and metadata, each item contains metadata, clusterName, and a data field holding the subresource response.
data— The subresource response body. If the Kubernetes API returns JSON (e.g.,statusorscale),datais the parsed JSON object. If the response is non-JSON (e.g., podlog),datais wrapped in a text envelope:{ text: "...", truncated: boolean }. Non-JSON responses are capped at 1 MB;truncatedistruewhen the response exceeded this limit.
Example Subresource Fact
Configuration:k8s_pods_status) in JSON:
Example: Collecting Pod Logs
Thelog subresource returns plain text, which is wrapped in a text envelope:
data field will contain: