Prerequisites
Configure Jira integration in Backstage
Integrations are configured at the root level ofapp-config.yaml. Here’s an example configuration for Jira:
- Basic authentication option:
- Personal Access token (bearer token) authentication option:
Add the JiraFactCollector to Soundcheck
First, add the@spotify/backstage-plugin-soundcheck-backend-module-jira package:
packages/backend/src/index.ts file:
packages/backend/src/index.ts
Plugin Configuration
The collection of Jira facts is driven by configuration. To learn more about the configuration, consult the Defining Jira Fact Collectors section. Jira Fact Collector can be configured via YAML or No-Code UI. If you configure it via both YAML and No-Code UI, the configurations will be merged. It’s preferable to choose a single source for the Fact Collectors configuration (either No-Code UI or YAML) to avoid confusing merge results.No-Code UI Configuration Option
- Make sure the prerequisite Configure Jira integration in Backstage is completed and Jira instance details are configured.
-
To enable the Jira Integration, go to
Soundcheck > Integrations > Jiraand click theConfigurebutton. To learn more about the No-Code UI config, see the Configuring a fact collector (integration) via the no-code UI.
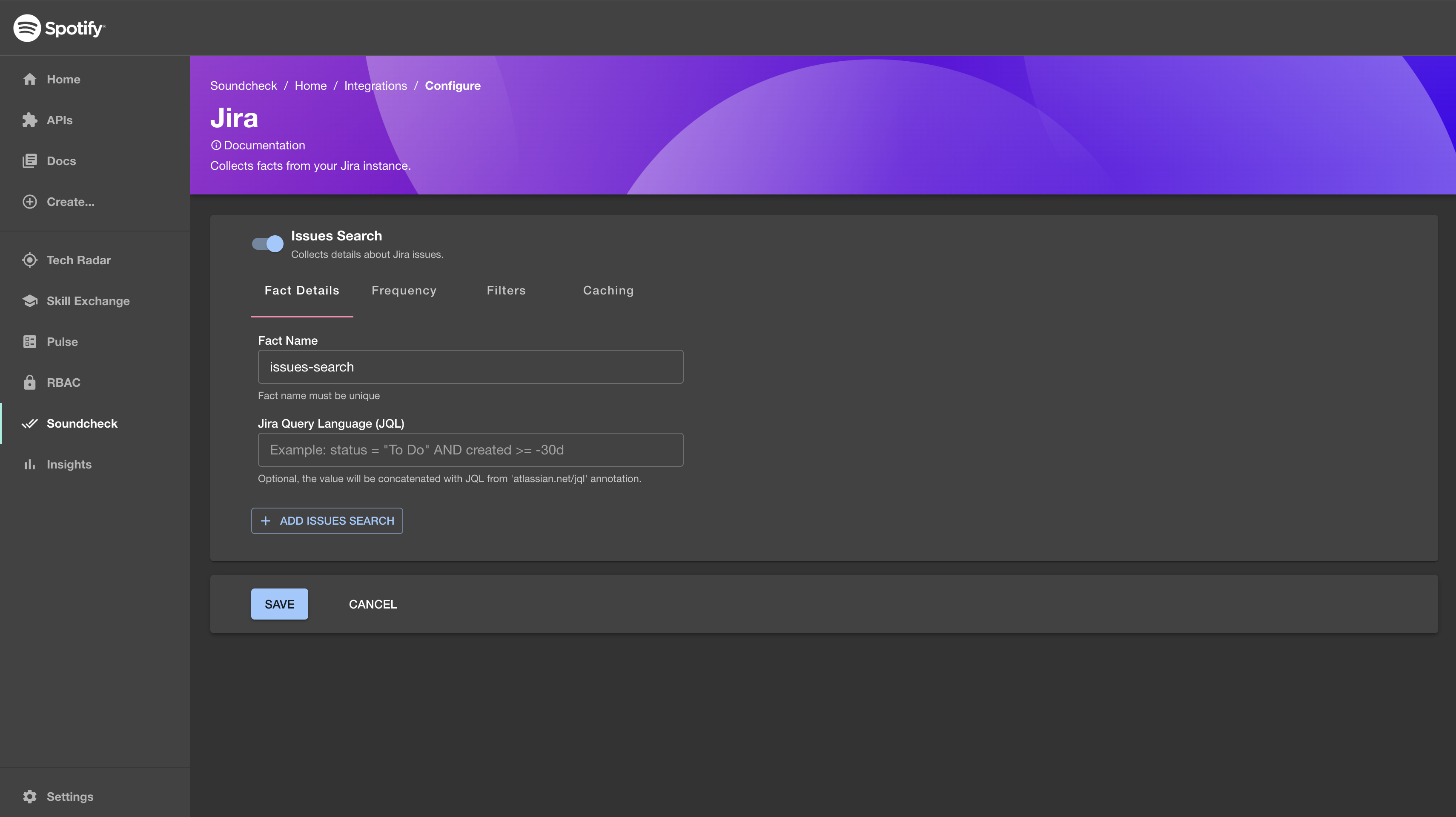
YAML Configuration Option
- Create a
jira-facts-collectors.yamlfile in the root of your Backstage repository and fill in all your Jira Fact Collectors. A simple example Jira fact collector is listed below.
app-config.yaml files.
- Add a Soundcheck collectors field to the
app-config.yamland reference the newly createdjira-facts-collectors.yamlfile.
Defining Jira Fact Collectors
This section describes the data shape and semantics of Jira Fact Collectors.Overall Shape Of A Jira Fact Collector
The following is an example of a descriptor file for a Jira Fact Collector:baseUrl [required]
The base URL of the Jira instance to use.
apiToken [optional]
Jira API token to use for basic authentication (together with username). If not provided, the plugin will attempt to use personalAccessToken as bearer token for authentication.
username [optional]
Jira username or email to use for basic authentication (together with apiToken). If not provided, the plugin will attempt to use personalAccessToken as bearer token for authentication.
personalAccessToken [optional]
Jira Personal Access token to use for authentication as bearer token. If not provided, the plugin will attempt to use username and apiToken for basic authentication.
collects [required]
An array describing which facts to collect.
Overall Shape Of A Fact Collector
Each collector supports the fields described below.type [required]
The type of the extractor (e.g. issues-search, issues-count).
frequency [optional]
The frequency at which the fact collection should be executed. Possible values are either a cron expression { cron: ... } or HumanDuration.
If provided, it overrides the default frequency provided at the top level. If not provided, it defaults to the frequency provided at the top level. If neither extractor’s frequency nor default frequency is provided, the fact will only be collected on demand.
Example:
initialDelay [optional]
The amount of time that should pass before the first invocation happens. Possible values are either a cron expression { cron: ... } or HumanDuration.
Example:
batchSize [optional]
The number of entities to collect facts for at once. Optional, the default value is 1.
Note: Fact collection for a batch of entities is still considered as one hit towards the rate limits
by the Soundcheck Rate Limiting engine, while the actual number of hits
will be equal to the batchSize.
Example:
filter [optional]
A filter specifying which entities to collect the specified facts for. Matches the filter format used by the Catalog API.
If provided, it overrides the default filter provided at the top level. If not provided, it defaults to the filter provided at the top level. If neither extractor’s filter nor default filter is provided, the fact will be collected for all entities.
See filters for more details.
exclude [optional]
Entities matching this filter will be skipped during the fact collection process. Can be used in combination with filter. Matches the filter format used by the Catalog API.
cache [optional]
If the collected facts should be cached, and if so for how long. Possible values are either true or false or a nested { duration: HumanDuration } field.
If provided it, overrides the default cache config provided at the top level. If not provided, it defaults to the cache config provided at the top level. If neither extractor’s cache nor default cache config is provided, the fact will not be cached.
Example:
jql [optional]
You can use the Jira Query Language (JQL) to specify criteria to search for issues in Jira.
Check out JQL docs for more examples.
Rate Limiting (Optional)
This fact collector can be rate limited in Soundcheck using the following configuration:Entity configuration
In yourcatalog-info.yaml file, add the following metadata annotation to allow the plugin to map an entity to a project in Jira.
Collecting Issues Search Fact
An Issues Search Fact contains information about issues from:- Get issues using JQL API for Jira Server (hosted) instances.
- Search for issues using JQL enhanced search API for Jira Cloud instances.
soundcheck.collectors.jira.collects[?(@.type === 'issues-search')].jql and metadata.annotations["atlassian.net/jql"], the plugin will concatenate them with an AND. Plugin will not remove any duplicate params.
This is useful if you want to create reusable facts, for example you can create fact that will look at issues with the status To Do like this:
jql to only look for issues with status To Do AND where project key is PROJECT. In your entity you would add following annotation:
(status="To Do") AND (project = "PROJECT") for all entities with tag someTagValue.
If there are 0 issues with status To Do for project PROJECT the check will be green, otherwise it will fail.
The following is an example response from Jira Issues Search API:
Collecting Issues Count Fact
An Issues Count Fact contains information about issues from:- Get issues using JQL API for Jira Server (hosted) instances.
- Count issues using JQL API for Jira Cloud instances.
soundcheck.collectors.jira.collects[?(@.type === 'issues-count')].jql and metadata.annotations["atlassian.net/jql"], the plugin will concatenate them with an AND. Plugin will not remove any duplicate params.
This is useful if you want to create reusable facts, for example you can create fact that will look at issues with the status To Do like this:
jql to only look for issues with status To Do AND where project key is PROJECT. In your entity you would add following annotation:
(status="To Do") AND (project = "PROJECT") for all entities with tag someTagValue.
If there are 0 issues with status To Do for project PROJECT the check will be green, otherwise it will fail.
The following is an example response from Jira Issues Count API.