Managing checks via the No-Code UI
Check Creation
Creating a custom check
To create a check, select the facts that you want to use, organize them into rules and give your check a meaningful name and a description.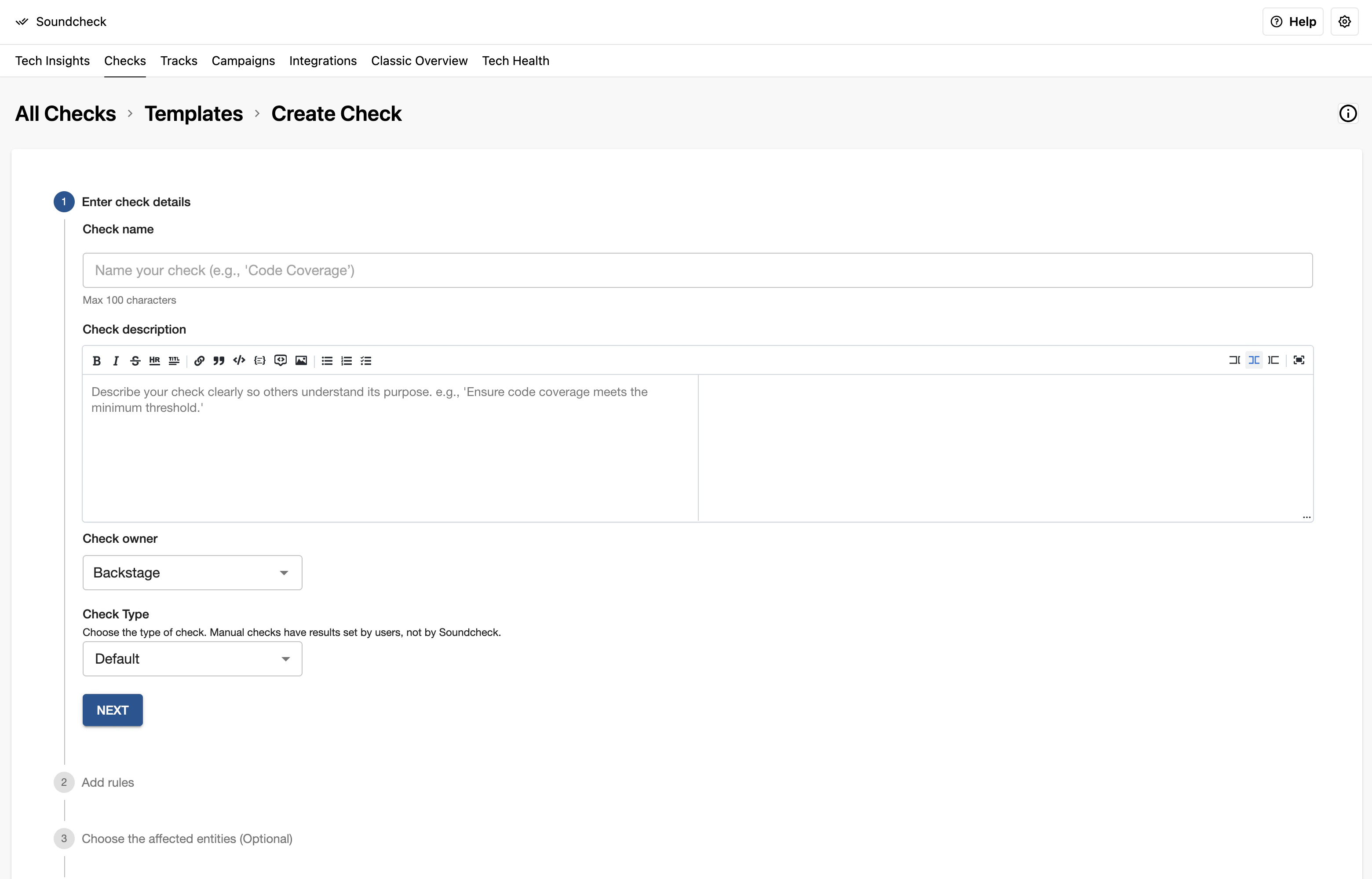
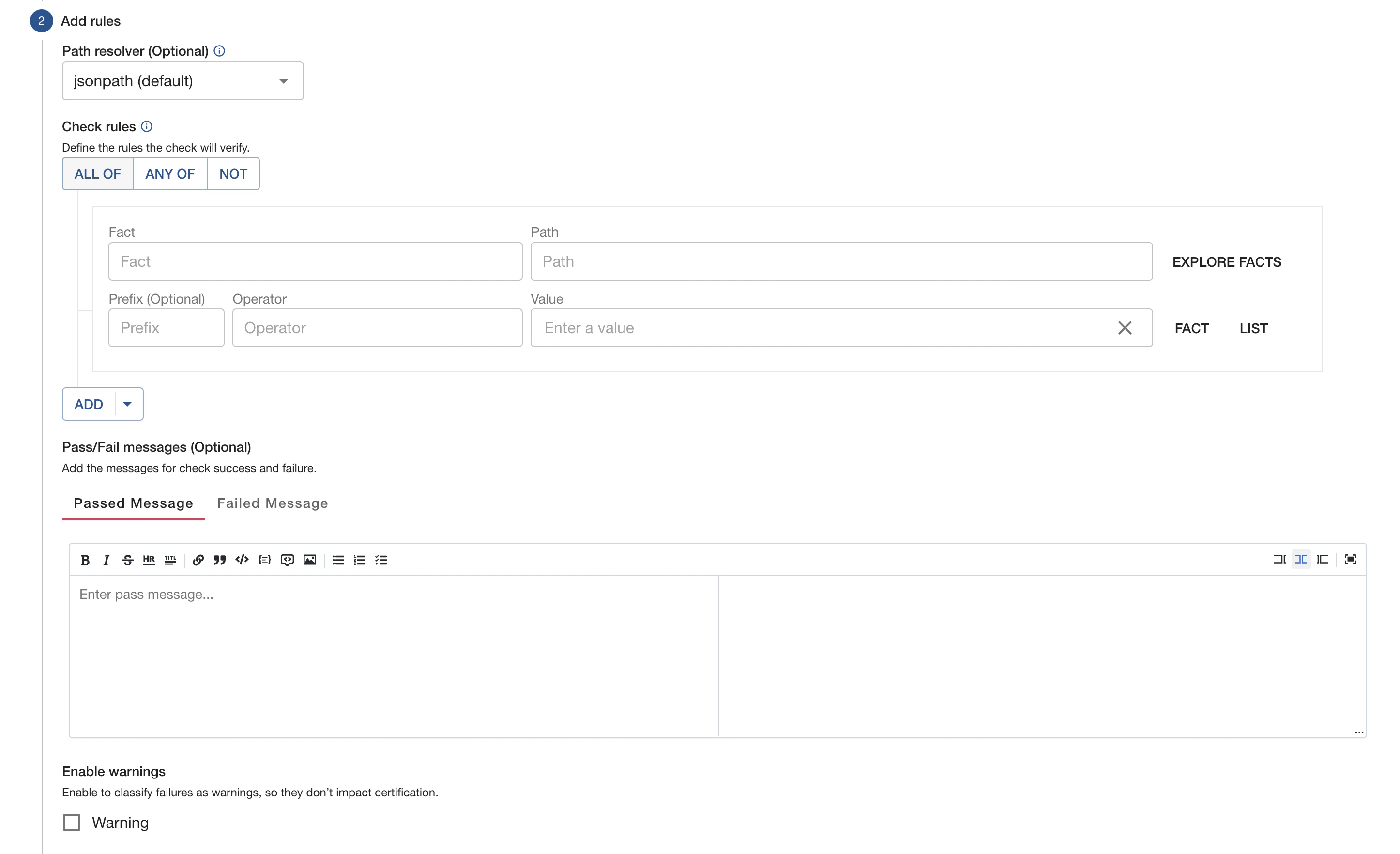
Creating a check from a template
Several check templates are included with Soundcheck depending on which integrations you have installed. These check templates prepopulate the create check form with a check name, description, rules, messages, and filters to help expedite the creation of common checks.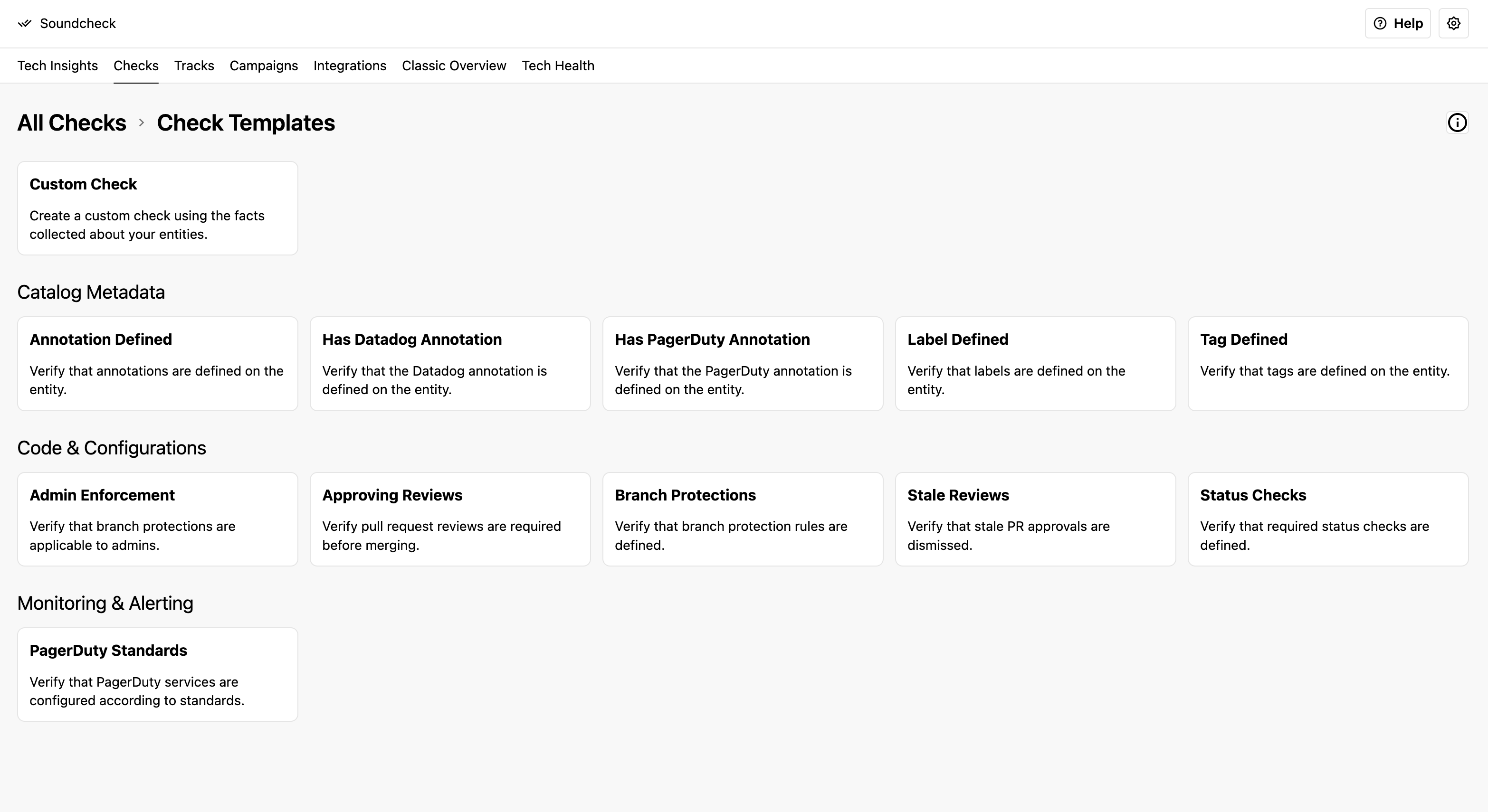
Editing a check
Once a check is created, you will be able to manage and edit your check on its detail page. You’ll find no differences in how the pages look when creating/editing a check. From the checks listing page, you will see an option to edit you check, which will bring you to the details page shown below.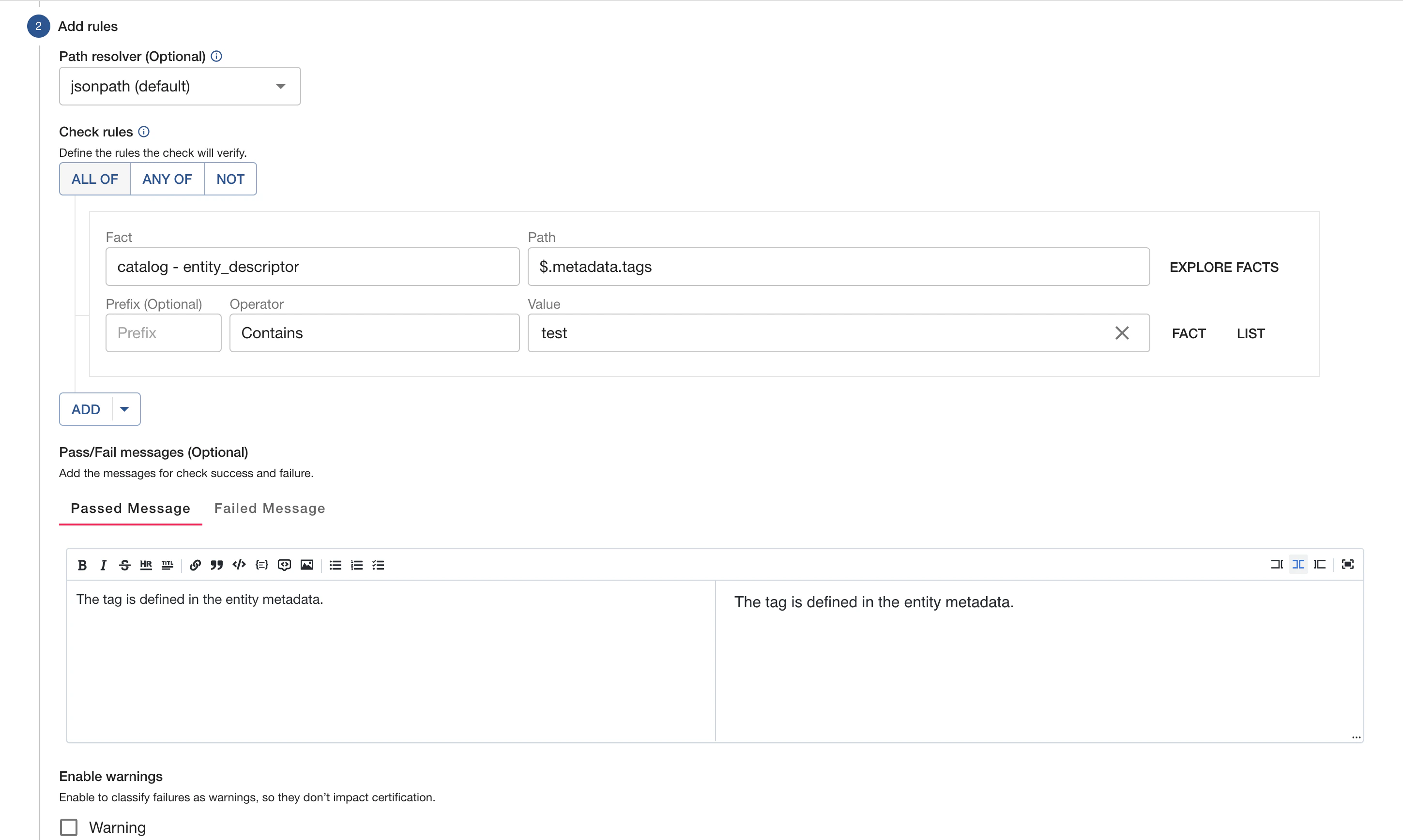
Configure mode for YAML-sourced checks
Checks defined in YAML configuration files (viaapp-config.yaml) cannot be edited and saved through the UI because they are not stored in the Soundcheck database. However, you can use Configure mode to work with these checks using the full form tooling.
When you open the action menu for a YAML-sourced check, a Configure button appears instead of Edit. Clicking it opens the check form in Configure mode, which:
- Opens directly to the Review step so you can immediately see the YAML preview.
- Lets you navigate back through all form steps to modify rules, filters, applicability, and other settings.
- Lets you dry-run the check against applicable entities, just like a normal edit.
- Replaces the Save button with an Export button that downloads the check as a YAML file.
- Replaces the Cancel button with a Close button that shows a confirmation dialog before discarding your changes.
Configure mode does not persist any changes to the database. To apply your
changes, export or copy the YAML and update your configuration files
(
app-config.yaml or the referenced YAML files) manually.Deleting a check
Checks can be deleted from the checks listing page or from the check detail page. When deleting a check, Soundcheck always removes current check results. A confirmation dialog includes an “Also delete check result history” checkbox that lets you choose whether to also delete historical results. When unchecked (the default), history is preserved so it remains available for reporting and trend analysis. The same option is available via the REST API (deleteHistory query parameter)
and the GraphQL API (deleteHistory argument). Both default to false.
Dry Run and Test a Check
Checks can be dry ran and tested in the Review and Test of the check form. This step can be viewed when both editing an existing check and creating a new check.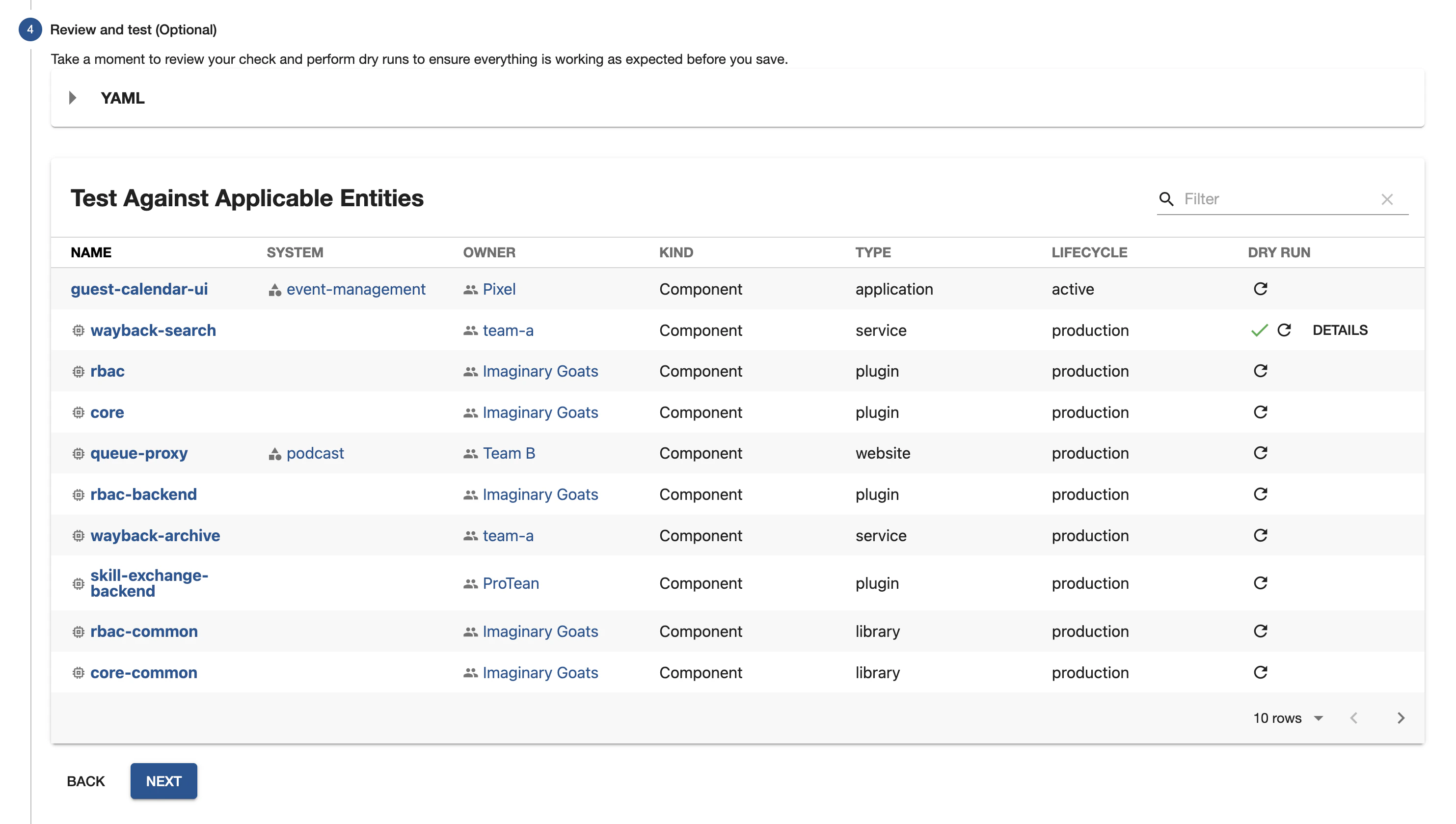

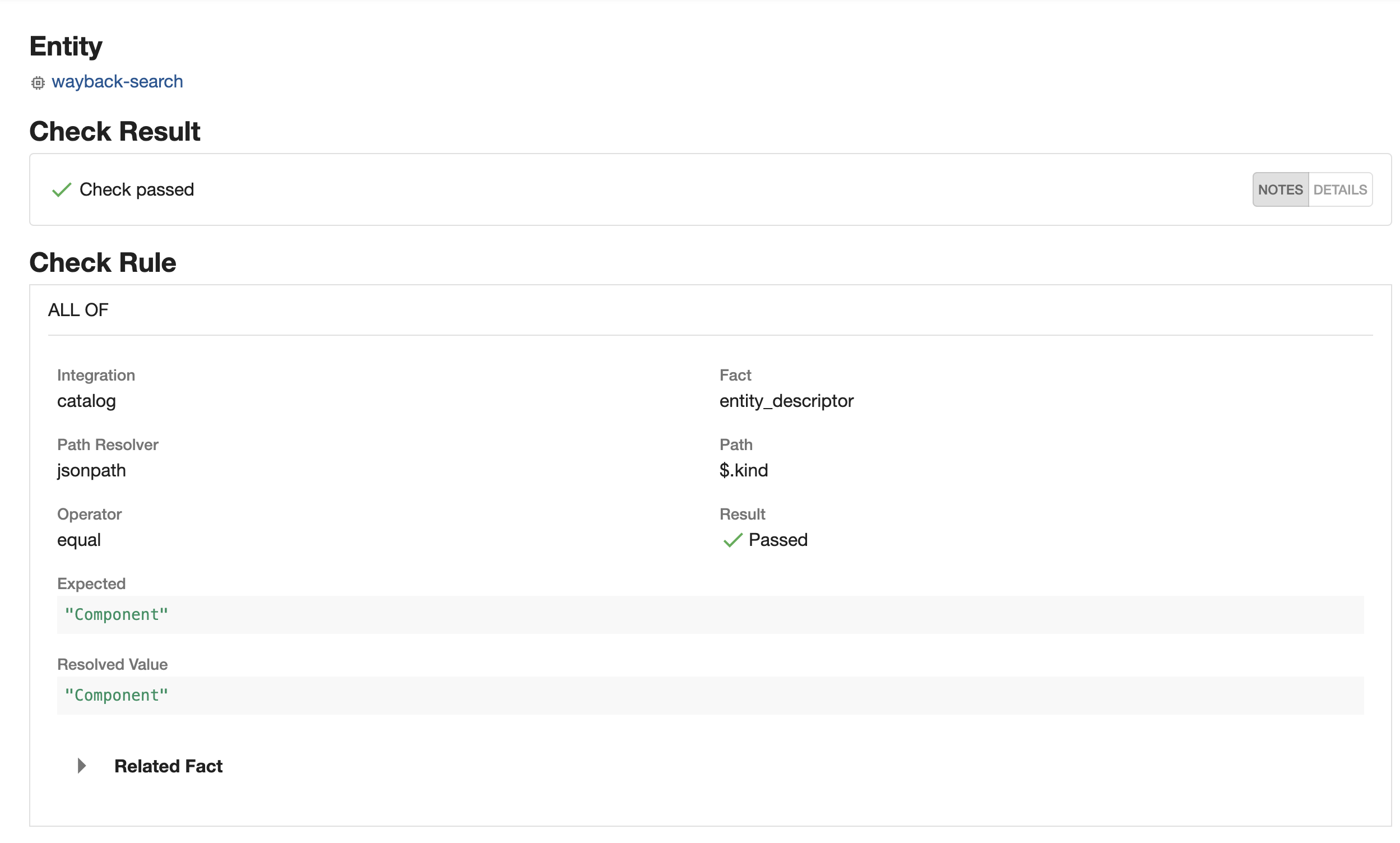
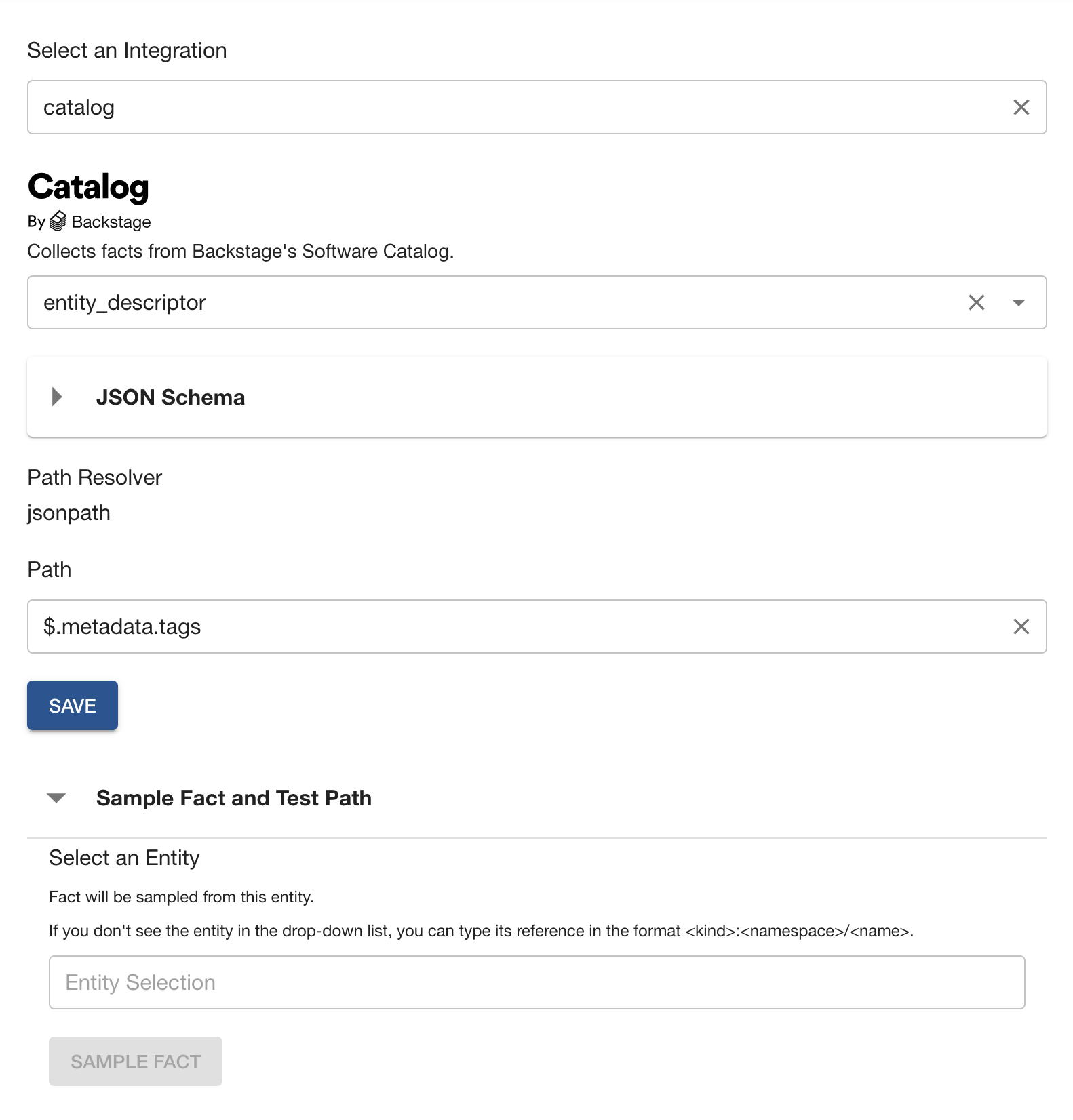
Fact Explorer
In the Check Form, facts can be explored via the Explore Facts button.
Export to YAML
Individual checks can be saved as YAML via the dropdown menu.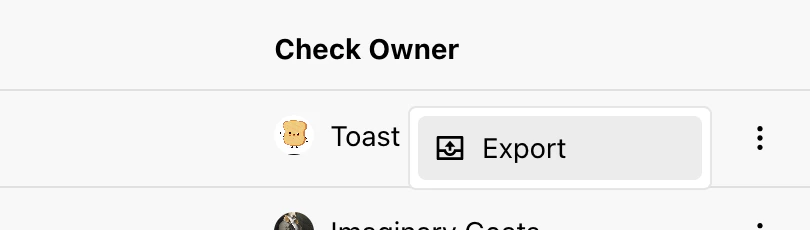
Export all checks button on the top toolbar.
Export entities to CSV
On a check’s detail page, the entity list can be exported to CSV using the Export button in the toolbar. The export respects any active filters (state, search, etc.), so the downloaded file contains exactly the entities visible on screen. The CSV includes the following columns: State, Name, System, Type, Lifecycle, Kind, Owner, Has Error, and Entity Ref. Owner, System, Type, and Lifecycle are enriched from the Backstage Software Catalog.Exports are limited to 5,000 entities. If the filtered list exceeds this
limit, a warning toast is displayed indicating how many entities were included
out of the total.
Import from YAML
Checks can be created from YAML via theImport YAML check(s) button on the top toolbar.
The checks will be created in the Soundcheck database and can be modified later just like other checks created via No-Code UI.
If using RBAC, make sure that your user has soundcheck.check.create permission.
- YAML file may contain either a single check or an array of checks.
- If the YAML file contains checks with IDs that already exist in Soundcheck, such checks will be skipped and the import will continue as normal.
- If one or more checks fail to import, their IDs will be listed in the warning banner and the import of the remaining checks will continue as normal.
Managing checks via yaml configuration
Checks can be created in code via yaml configuration files.Overall shape of a Check
A fact check (or more commonly, just a ‘check’) defines a rule comprised of one or more conditions: a combination of facts, operators, and values that determine whether the check emits apassed or failed check result to Soundcheck.
Note: the id field is a unique identifier for the check. It is used to reference the check in tracks and within the Soundcheck UI. It must be unique across all checks in your library.
Soundcheck supports both checks defined in yaml files and via a no-code UI.
Checks defined in yaml files can be sourced locally or remotely, and require only
two fields: id and rule.
Here is an example of a basic check defined in yaml (more examples):
$.metadata.annotations['pagerduty.com/integration-key'] pagerduty.com/integration-key is escaped with ''.
Adding yaml checks to your check library
To add checks defined in a yaml file to your check library, you need to source them in youapp-config.yaml. You have the option of storing them locally or remotely.
Here is an example configuration should your check yaml files be local to your Backstage project:
app-config.yaml
app-config.yaml in a similar manner. Here is an example configuration:
app-config.yaml
Note: you cannot combine local and remote sourcing for checks files. This includes the usage of $include within a remotely sourced checks file. The below option will NOT work:
app-config.yaml
Remote file update options
Theremote_file_updates object is optional configuration allowing you to control if and when Soundcheck looks for updates within your remote files. This configuration is global for Soundcheck, so will apply to both track and check files. If not explicitly set, see the below for default values.
Migrating checks from yaml to no-code UI
To migrate the checks from yaml to no-code UI follow these steps:- Remove references to checks from
soundcheck.checksconfiguration. - Import yaml checks previously referenced in
soundcheck.checksconfiguration using the “Import from YAML” button located on the Checks tab in the UI.
Check Fields
The
name and description fields can be used to provide more context to the check.
If not provided, the id will be used as the name when viewing the check in Soundcheck.
When creating checks via the no-code UI, the name, description, and owner, fields become required.
Rules
A rule contains one or more conditions. The simplest form of a condition consists of a fact reference, an operator, and a value. When the check is executed, the operator is used to compare the fact against the value. Example of a simple condition:all, any, or ‘not’ expression at its root, containing an array of
conditions. The all operator specifies that all conditions
contained within must be truthy for the check to pass. The any operator only requires one
condition to be truthy for the check to pass, while the not operator negates the result of the
condition it contains.
Example of a complex condition:
Value Input
The rule value can be a singular or a list, or an object with another fact. Example using a list of values:Path Resolvers
Thepath field in a rule is used to resolve a path to a value in a fact, and it is this resolved value that is used in
the comparison with the value field. This allows you to reference specific parts of a fact to compare against a value.
Soundcheck supports multiple path resolvers, which can be specified in the pathResolver field of a check. If no path
resolver is specified, Soundcheck will use its default path resolver (JSON Path).
The path resolver option applies to all rules for a check.
Example:
jsonpath- defaultlodashjmespathjsonata
JSON Path
Soundcheck’s default path resolver. JSONPath is a query language for JSON, similar to XPath for XML. It allows you to navigate and filter JSON data to extract specific values or sets of values. JSONPath expressions are used to traverse the JSON data structure and extract the data that matches the expression.Key Features of JSONPath:
- Dot Notation and Bracket Notation: You can use dot notation (
$.store.book[0].title) or bracket notation ($['store']['book'][0]['title']) to navigate the JSON structure. - Wildcard (
*): Selects all elements in an array or all properties in an object. - Recursive Descent (
..): Searches recursively through the JSON structure. - Filters: Allows you to filter JSON data based on expressions. For example,
$.store.book[?(@.price < 10)]selects books with a price less than 10. - Slicing: Similar to array slicing in Python, e.g.,
$.store.book[:2]selects the first two books.
$.store.book[*].authorreturns["Nigel Rees", "Evelyn Waugh"]$.store.bicycle.colorreturns"red"$..pricereturns[8.95, 12.99, 19.95]$.store.book[?(@.price < 10)].titlereturns["Sayings of the Century"]
Lodash Get
lodash.get is a utility function from the Lodash library, which is a popular JavaScript utility library. Theget
function is used to access deeply nested properties in objects.
Key Features of lodash.get
- Path Notation: You can specify the path to the property using a dot notation string or an array of keys.
- Simplicity: Easy to use syntax.
'store.book[0].author'returns"Nigel Rees"
JMES Path
JMESPath is a query language for JSON, designed to allow you to extract and transform elements from JSON data structures. Similar to JSONPath, it enables you to navigate and filter JSON data, but it has its own syntax and features.Key Features of JMESPath:
- Dot Notation: Used to navigate through JSON objects. For example,
foo.barwill navigate to thebarproperty of thefooobject. - Filters: Allows filtering of arrays. For example,
foo[?bar > 10]will filter thefooarray to include only elements wherebaris greater than10. - Projections: Allows transformation of arrays and objects. For example,
foo[*].barwill create a list of thebarproperties from each object in thefooarray. - Functions: JMESPath includes built-in functions such as
length,max,min,sum, andcontains.
store.book[*].authorreturns["Nigel Rees", "Evelyn Waugh"]store.bicycle.colorreturns"red"store.book[?price > 10].titlereturns["Sword of Honour"]store.book[?category == 'fiction'].pricereturns[12.99]
JSONata
JSONata is a lightweight query and transformation language for JSON data. It allows you to query, filter, and transform JSON data in a concise and expressive way. JSONata includes features for selecting data, performing calculations, and creating new JSON structures based on existing data.Key Features of JSONata:
- Expression Language: JSONata expressions enable complex querying and transformations of JSON data.
- Path Notation: Similar to XPath for XML, JSONata uses a path notation to navigate through JSON structures.
- Functions: JSONata includes built-in functions for manipulating data, such as mathematical operations, string operations, and more.
- Conditionals: You can use conditional expressions to filter and transform data based on specific criteria.
- Mapping and Reducing: JSONata supports mapping and reducing operations to transform arrays and objects.
store.book.authorreturns["Nigel Rees", "Evelyn Waugh"]store.bicycle.colorreturns"red"store.book[price < 10].titlereturns["Sayings of the Century"]store.book.{ "title": title, "cost": price }returns:
Operators
Boolean, Numeric, & String Operators
These operators support boolean, numeric, and string values.
When dealing with arrays of booleans, numbers, or strings, these operators can be used in combination with the
all:,
any:, and none: prefixes to validate the elements of the array. See the Array Operators section
for additional details.
Numeric Operators
These operators support only numeric values.
When dealing with arrays of numbers these operators can be used in combination with the
all:, any:, and none:
prefixes to validate the elements of the array. See the Array Operators section for additional details.
String Operators
These operators support only string values.
When dealing with arrays of strings these operators can be used in combination with the
all:, any:, and none:
prefixes to validate the elements of the array. See the Array Operatorssection for additional details.
SemVer Operators
These operators support only string values that represent semantic versions or semantic version ranges.
When dealing with arrays of string representing semantic versions or semantic version ranges these operators can be used
in combination with the
all:, any:, and none: prefixes to validate the elements of the array. See the
Array Operators section for additional details.
Date/time Operators
These operators support string values in ISO 8601 date/time or duration format. Negative durations are also supported:-P1Y will be interpreted as 1 year before check execution. Additionally, Soundcheck
supports the use of the now keyword to represent the current date/time.
Exists Operator
A value of “true” or “false” must be provided for this operator. Using “true” will expect the Fact value to exist, whereas using “false” it will expect the Fact value to NOT exist in the Fact.
When dealing with arrays this operator can be used in combination with the
all:, any:, and none: prefixes to
validate the elements of the array. See the Array Operators section for additional details.
Array Operators
These operators support array values.
Additionally, you can use the following prefixes in combination with any of the above operators to validate the elements
of an array:
all:- Validates that all elements in the array satisfy the condition.any:- Validates that at least one element in the array satisfies the condition.none:- Validates that none of elements in the array satisfies the condition.
greaterThan operator with
the all: prefix:
Schedule
NOTE: Check scheduling will be deprecated soon, make sure your fact collectors are scheduled instead. When Soundcheck collects a fact it will automatically execute all checks that depend on that fact.Scheduling options for fact checks:
Messages
- Pass messages -
passedMessage- are displayed to the user when a check passes. - Fail messages -
failedMessage- are displayed to the user when a check fails. - Not applicable messages -
notApplicableMessage- are displayed to the user when a check is determined to be not applicable based onapplicableconditions.
entity- The entity the check was executed on.facts- A map of facts used by the check. Individual facts can be looked up in this map by fact reference. For example,facts['catalog:default/entity_descriptor'].- If all the facts used by the check have unique fact names they can be accessed in
factsby fact name rather than having to use the entire fact reference. For example, if check uses thecatalog:default/entity_descriptorit can be accessed byfacts['catalog:default/entity_descriptor']orfacts['entity_descriptor']. - If only a single fact is used by the check, the fact can be accessed directly. For example, if
catalog:default/entity_descriptorwas the only fact used by the check it can be accessed asfactrather thanfacts['catalog:default/entity_descriptor'].
- If all the facts used by the check have unique fact names they can be accessed in
Example - Using the Entity Object
Here is an example of a pass message using templates:{{ entity.metadata.name }} with the name of the entity the check was
executed on.
This would resolve to:
Example - Check Fail Message With a Single Fact
Given this check with the following rule:fact property in our failed message.
Example - Check Fail Message with Multiple Facts
Given this check with the following rule:facts property.
To create a message with the kubernetes fact:
Example - Testing JSON Output
To see the facts available it is recommend to use the fact explorer or the check dry run in order to get the fact information. These features are available in the check form. Check dry runs will also fully resolve the pass/fail message. You can also render the output as JSON. This is particularly useful for displaying facts for testing and debugging. Wrap in a code block to preserve formatting. For example:facts object:
Markdown Support
Pass/fail messages support nested markdown within a<details> block. For example:
Sensitive Facts
Some facts are considered sensitive and cannot be used for templating without explicitly enabling this feature. See docs for details.Filters
Checks can be filtered to the desired set of entities using catalog filters, with the exception of theCATALOG_FILTER_EXISTS symbol.
NOTE: Specifying a filter on a check sets the default filter for the check. This filter is used when the check is added to a Track using Soundcheck’s UI. If using YAML to define Tracks, the filter must be set on the check within the Track itself.Note that check schedules also allow a filter to be set. You may configure your check to use either filter, or both. The schedule’s filter is used to determine which entities the check should run on when the schedule is triggered. Very commonly, the schedule’s filter is the same as the check’s filter, implying that the scheduled check should run on the same set of entities to which the check applies, but this need not be the case. For example, say you have a set of components to which a check applies, but only expect a subset of those entities to change with any regularity. You could set the check’s filter to the set of all components to which the check applies, and the schedule’s filter to the subset of components that are expected to change more frequently. This setup would allow you to save on compute and rate limits (in the event the check relies on a fact from an external source, such as SCM or Github), while still ensuring that the check is applicable to all entities to which it should apply. You can also set an exclusion filter using the
exclude property for both applicability and scheduling.
You must use filter if you are using the exclude property.
See filters for more details.
Check Filter Examples
Here is an example of a check with a filter set to limit the check to only apply tocomponents of
type service, and exclude any entities with a tag of skip:
- The scheduling of checks is not recommended. Instead, schedule the collection of facts that the check depends on through the Fact Collectors’ configurations. Collection of facts will trigger the execution of all checks that depend on those facts. The exception to this recommendation is when you have checks that rely on facts from the Software Catalog or TechInsights, both of which must be scheduled checks.
- Scheduling a check without a filter will run the check on all entities in the catalog, regardless of the check’s top-level filter. This is not recommended.
Applicability Rule
Check applicability rules can be used when standard catalog filters are not enough to determine applicability. These determine applicability at the same time check rules are, and can utilize collected facts.Note: Prefer using catalog filters as these prevent non-applicable checks from executing. Applicability rules can be computationally expensive.When both catalog filters and applicability rule are defined, the check will be applicable to the entities that both match the catalog filters and pass the applicability rule. Some pages will show the check until the applicability is evaluated. Once evaluated, not applicable checks will not be shown on the Soundcheck for Entity page by default. To view the not applicable checks, click on the small gear icon beside the list of Tracks for the component, and select
Show Not Applicable Checks:

applicabile condition):
Executing Checks
Fact checks are executed by Soundcheck:- When a dependent fact is updated.
- Via scheduled execution based on frequency and entities.
- Manually triggered via the Checks API.
- Manually triggered by clicking on Execute Check icon (⟳) on Soundcheck Entity Tab.
Examples
Push Workflow
Soundcheck supports a basic push workflow via our Facts API instead of using a fact collector. Facts sent to this API will automatically run checks associated with the fact’sfactRef and entityRef.
Check Creation - UI
In the UI, instead of selecting a fact from the drop down, you will type in the fullfactRef as seen below in the screen shot. This factRef must be the same as the one you plan to call the Fact API with.

- Dry runs will not work.
- Manually running the check will not work.
- The fact will not show up in the dropdown lists.
Check Creation - YAML
Check creation in YAML is no different from a standard check. Make sure to utilize the samefactRef you will be calling the Fact API with.
Testing Your Check
You will not be able to manually run a check from the UI like with a standard check. To test your check, make an API call to the Facts API after check creation with thefactRef for the check and the entityRef of the entity you want to test.
Soundcheck will enqueue and execute checks relevant to this fact and entity after receiving this API call.
REST API
We include a REST API for Checks. See API Reference for details.Check Result History
By default, Soundcheck retains historical results of checks for 120 days. When a check is deleted or its rule is updated, history is preserved by default. You can choose to delete history at the time of the operation via the “Also delete check result history” checkbox in the UI, or thedeleteHistory parameter in the API. See
Deleting a check and Editing a check
for details.
Other systems can integrate with check result history by reading from the
Soundcheck database directly. Check histories can be seen in the Soundcheck UI
on the Tech-Health pages, and on the check insights pages (the default view when
clicking on a check in the Soundcheck UI).
Modifying Check Result History Settings
To disable check result history, setsoundcheck.results.history.enable to false
in the config (no value or a value of true will leave it enabled). For example:
app-config.yaml
retentionTimeInDays. For example, this config
will instruct Soundcheck to retain history for the past year:
app-config.yaml
app-config.yaml
Appendix
Recommended GitHub Settings Checks
Pre-builtRecommended GitHub Settings checks are based on the GitHub collector
configuration and defined as follows:
Basic SCM Compliance Checks
Pre-builtBasic SCM Compliance checks are based on the SCM collector
configuration and defined as follows: